



安排!洛杉矶母亲节周末活动精选
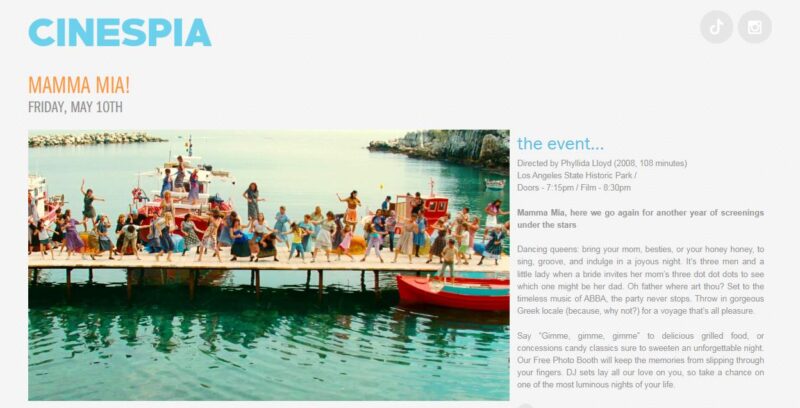
妈妈咪呀!母亲节即将在5月12日(周日)来临。按照传统,庆祝母亲节的方式多种多样,就像玫瑰花的花瓣一...
2024-05-08阅读(8460)赞 (42)
















































妈妈咪呀!母亲节即将在5月12日(周日)来临。按照传统,庆祝母亲节的方式多种多样,就像玫瑰花的花瓣一...
2024-05-08阅读(8460)赞 (42)

5月8日(周一)晚间,在纽约大都会艺术博物馆慈善晚会(Met Gala)上,明星们身着泥土色服装,受...
2024-05-08阅读(8660)赞 (17)

苹果(Apple)希望其最新的iPad系列能为其低迷的平板市场注入新的活力。在加州库比蒂诺总部举行的...
2024-05-08阅读(10445)赞 (37)
据报道,Panera Bread将在接下来的两周内从菜单中取消“充电柠檬水(Charged Lemo...
2024-05-08阅读(11340)赞 (9)

美国童子军(Boy Scouts of America)5月7日(周二)宣布,将于2025年2月8日...
2024-05-08阅读(11486)赞 (44)
